5 Reasons why your organization needs a data engine
In an increasingly data-driven world, businesses are leveraging data to gain a competitive advantage. At the same time, the amount of data they accumulate at the edge and in the cloud is massive and eventually becomes difficult to manage. With legacy data models, diverse and disconnected data formats, companies that want to take advantage of the benefits data can offer often end up drowning in unusable, low-quality data. Hence, using a scalable data engine to process and transform this data into high-quality data becomes essential for businesses who see using data as a core component to their business operations.
This blog article was transformed from our video, 5 Reasons Why You Need a Data Engine. You can check it out on our YouTube channel.
Table of Contents
What is a Data Engine?
A data engine is a powerful data processing framework that is designed to convert raw data into structured events. It follows the general flow of bringing distributed data sources together into a data pipeline, performing data fusion, injecting data analytics and generating meaningful event data that can be used in a variety of applications.

A data engine can use a variety of different raw data sources
Machine Data: Machine data refers to data that is generated by machines and devices. This includes data from sensors, machine logs, and other automated sources. Machine data is typically unstructured and can be difficult to process using traditional data analysis tools. However, data engines are specifically designed to handle large volumes of unstructured data, making them well-suited for processing machine data.
Operational Data: Operational data refers to data that is generated by business operations. This includes data from customer interactions, financial transactions, and supply chain operations. Operational data is typically structured and can be processed using traditional data analysis tools. However, data engines can provide real-time insights into operational data, allowing organizations to optimize operations and improve customer experiences.
Software Data: Software data refers to data that is generated by software applications. This includes data from user interactions, application logs, and system performance metrics. Software data is typically structured and can be processed using traditional data analysis tools. However, data engines can provide real-time insights into software data, allowing organizations to optimize application performance and improve user experiences.
Sensor Data: Sensor data refers to data that is generated by physical sensors. This includes data from temperature sensors, pressure sensors, and motion sensors. Sensor data is typically unstructured and can be difficult to process using traditional data analysis tools. However, data engines can provide real-time insights into sensor data, allowing organizations to monitor and optimize physical operations.
Logbook Data: Logbook data refers to data that is generated by various activities and operations of an organization. This includes data from system logs, server logs, and network logs. Logbook data is typically unstructured and can be difficult to process using traditional data analysis tools. However, data engines can provide real-time insights into logbook data, allowing organizations to monitor and optimize their systems and networks.
How Does Data Move Through the Data Engine?
The data engine converges data from all the data sources spanning from sensor data from the edge to the cloud data, and puts them through a 4-step process to give meaningful context to the data that enables different applications to further take place.
Data Pipeline: A data pipeline is a series of interconnected steps that move data from one location to another while performing various transformations and enrichments along the way. The pipeline typically includes stages such as ingestion, processing, and storage, and it can be either batch-oriented or real-time. A well-designed data pipeline ensures data is accurate, reliable, and available for downstream use.
Data Fusion: Data fusion is the process of combining data from multiple sources to create a more complete and accurate view of the underlying phenomena. It involves the integration of data from various formats, resolutions, and domains, and the resolution of conflicts and inconsistencies that arise. Data fusion enables organizations to gain a deeper understanding of complex systems and make more informed decisions.
Data Analytics: Data analytics refers to the process of extracting insights and knowledge from data by applying statistical and machine-learning techniques. It involves the identification of patterns, trends, and correlations in data, and the development of models that can be used to make predictions and optimize processes. Data analytics is essential for data-driven decision-making and for identifying opportunities for improvement.
Event Generation: Event generation is the process of detecting and reacting to events in real time. It involves the identification of patterns and anomalies in data streams and the triggering of actions based on those patterns. Event generation is critical for real-time monitoring and control of complex systems, and it enables organizations to respond quickly to changing conditions and take advantage of opportunities.
Why Organizations Should Use A Data Engine
Organizations that have both data at the edge and in the cloud, or have massive amounts of unstructured data can significantly benefit from managing their data with a data engine. The data engine is key to bringing benefits across teams by reducing data complexity, reducing data volume, enabling BI analysis, accelerating DataOps, and developing a resource-efficient architecture. We break it down into 5 reasons below:
A data engine reduces data complexity
A data engine is designed to extract events from time-series data, which can help to simplify the data and reduce its complexity. By breaking down the raw data into structured events, it becomes easier to analyze and interpret the information. This can help organizations to gain deeper insights into their data and make more informed decisions.

As you can see in the image above, time-series data is typically timestamped and comes in at regular intervals. While you can identify events in the data, it may be difficult to understand their significance without context. This is where the data engine comes in, as it extracts events from the time series data and combines multiple data tags to describe the process.
For instance, an event could be a production run and may include properties such as the run's success, duration, operator, warning codes, and efficiency. By converting many raw data tags into one event data tag, the data engine significantly simplifies the complexity of operational data, making it clear and structured. This is crucial because engineers and data analysts can easily analyze meaningful operational data, which would otherwise be difficult to understand.
2. A data engine reduces data volume
The value in reducing data often raises debate because data storage is relatively cheap nowadays. However, even though data storage may be inexpensive, the constant influx of data can quickly accumulate to a massive volume, which becomes very costly to manage. In fact, many industrial processes don't store all their data in data lakes, as file storage systems such as Amazon S3 are a more economical option.

This is where data volume and data bandwidth transfer costs come into play. By converting raw data into events, the amount of data can be reduced by a factor of a thousand or even ten thousand, depending on the frequency of the events. This significant reduction in data volume leads to faster and simpler extraction of insights, making it a critical advantage for any organization.
3. A data engine enables business insight analysis
One of the benefits of using a data engine is that it enables easy business insight analysis. Once raw data is converted into events and stored in a database or data warehouse, BI analysis becomes much simpler.

With BI analysis, organizations can gain insights into their operations, such as overall efficiency over time, operator performance, which machines need maintenance, and identifying error codes and how to prevent them. It's difficult to perform BI analysis directly on raw operational data, which is why converting the data into events is so valuable.
4. A data engine accelerates DataOps development
Using a data engine provides a framework for quickly developing data operations solutions with high performance. A typical DataOps engine is visual, making it easier to observe and develop solutions. It is also modular and hierarchical, which reduces the complexity of the design.
The self-documenting feature allows developers to understand the flow of data operations without being experts in software coding.

A data engine typically has a powerful architecture that is asynchronous, meaning it consumes minimal resources when there is no data coming in, and it can spin off tasks into containers that run independently when there is a lot of data coming in.
This makes it possible to scale to large data operations. Data engines must also support physics and AI models because converting raw data into events often requires advanced analytics. Finally, a data engine should provide work versioning and data lineage tracking capabilities to keep track of any issues.
5. A data engine creates a resource-efficient architecture
Scaling your data engine into a distributed architecture, also known as a data mesh architecture. This approach allows you to have multiple data engines ready to serve different data sources, whether they're in the cloud or at the edge of a plant or refinery.
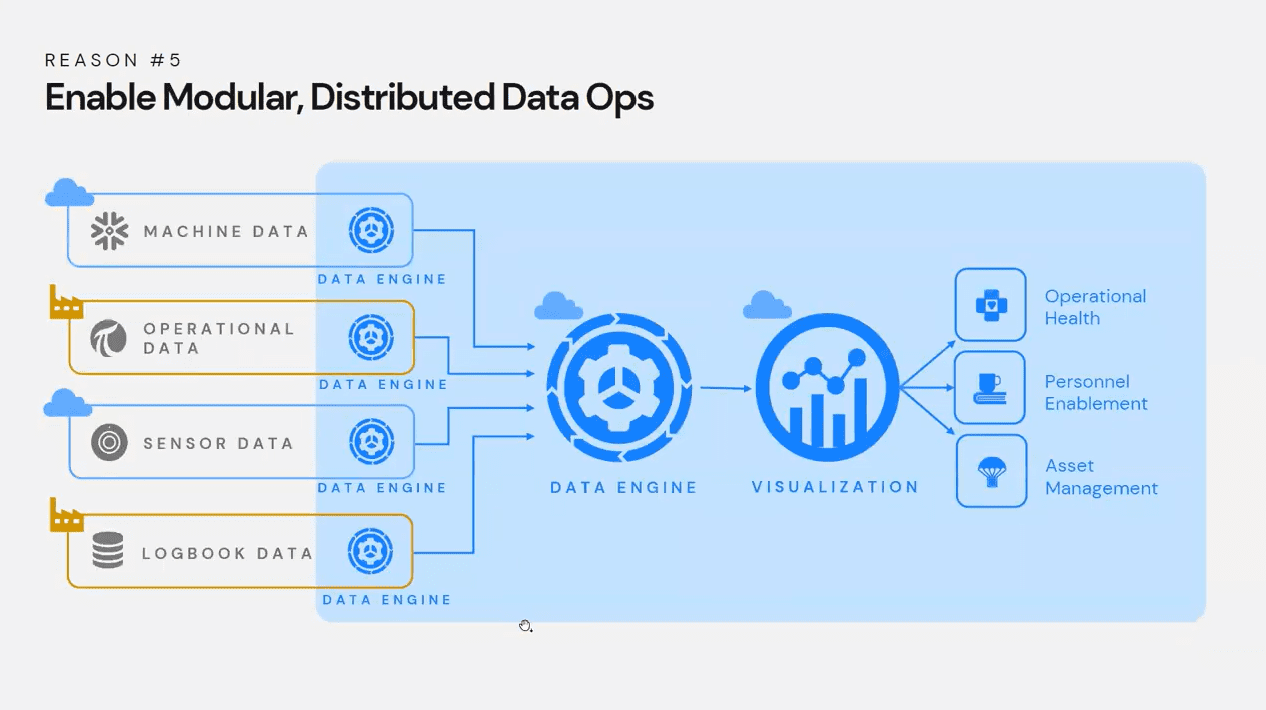
This is particularly useful for organizations where data is distributed across multiple locations and cannot be collected in one place due to security or privacy concerns. By bringing the data engines to where the data resides, you can process the data locally and send out insights without compromising privacy or security.
This approach also allows you to combine data from all sources into a comprehensive data insights solution, making it a powerful tool for scaling large data operations to serve physical operations and processes.
Conclusion
In conclusion, data engines are a powerful tool for organizations that need to extract insights from large volumes of data. By reducing data complexity, reducing data volume, and providing a comprehensive view of the data, data engines can help organizations make better decisions, improve their operations, and optimize their processes. With their scalable architecture and powerful data processing capabilities, data engines are an essential component of any modern data processing workflow.
This is our approach to managing massive and complex data from the edge and the cloud. If you would like to help your organization leverage your distributed data sources, please schedule a free demo. We would love to know more about your project.